基本数据类型
什么是数据类型 : 是用来存储值的所在处,它们有名字和数据类型。的数据类型决定了如何将代表这些值的位存储到计算机的内存中。在声明时也可指定它的数据类型。所有都具有数据类型,以决定能够存储哪种数据
Python提供的基本数据类型主要有:布尔类型、整型、浮点型、字符串、列表、元组、集合、字典等等。
整形&浮点型
整形也就是整数类型(int),存放年龄,工资,成绩等,有正整数,负整数和零,浮点型也就是小数类型(folat),带小数点的
- a = 10
- b = -20
- c = 0.05
布尔类型
布尔类型就是真和假,只有这两种,True和Fasle,非真即假,除了True和False还有0和1,非0即真
- a = True
- b = False
字符串操作


1 name = 'my name baylor' 2 name = 'my name \tis {name} and I am {year} old' 3 print(name.capitalize()) #首字母大写 4 print(name.count('i')) # 计算 i 出现几次 5 print(name.center(50,'-')) #一共打印50个字符,不够用 - 补齐 name放中间 6 print(name.endswith("baylor")) #判断字符串 以什么结尾 返回true 7 print(name.expandtabs(tabsize=30 )) #在字符串中输入 '\t' tabsize 增加30个空格 8 print(name.find('name')) #返回 下标 9 print(name[name.find('name'):9]) #切片 返回name10 print(name.format(name='baylor',year = 23))11 print(name.format_map({ 'name':'baylor','year':'23'})) #字典12 print('ab123'.isalnum()) #包含字母数字13 print('asdA'.isalpha()) #纯字母14 print('123'.isdecimal()) #纯数字15 print('1'.isdigit()) #是否为整数16 print('a1A'.isidentifier()) #判断是不是一个合法的标识符=变量名17 print('a123'.islower()) #判断字符串 是不是小写18 print('123'.isnumeric()) #是否是一个数字(只有数字)19 print(' '.isspace()) #是否为空格20 print('My Name Is '.istitle()) #判断每个词的首字母是否大写21 print(' mdf'.isprintable()) #如果是字符串不用考虑,tty.file drive.file 文件打印22 print('ZXC'.isupper()) #是否为大写23 print('+' .join(['1','2','3'])) #例子: 1+2+324 print(name.ljust(50,'*')) #字符串字节长50,不够右以*补齐25 print(name.rjust(50,'*')) #字符串字节长50,不够左以*补齐26 print('Baylor'.lower()) #把大写变成小写27 print('Baylor'.upper()) #把小写变成大写28 print('\nbaylor'.lstrip()) #去掉左边的 空格&回车29 print('\nbaylor\n'.rstrip()) #去掉右边的 空格&回车30 print('\nbaylor\n'.strip()) #去掉左右俩边 空格&回车31 p = str.maketrans('abcdef','123456')32 print('fedcba'.translate(p)) #随机密码33 print('baylor'.replace('y','Y')) #替换 replace('y','Y',1)34 print('baylor'.rfind('i')) #从左到右查询 返回 查询最后一位下标返回35 print('jin yu in'.split()) #按空格分成列表36 print('1+2+3+3'.split('+')) # ['1', '2', '3', '3']37 print('1+2+\n2+3'.splitlines()) #按换行符分成字典38 print('Baylor'.swapcase()) #大小 互转 print(name.startswith(‘m')) #判断一个文本是否以某个或几个字符开始,结果以True或者False返回39 print('baylor'.title()) #首字母大写40 print('baylor'.zfill(50)) #50个字符,不够左侧补0 41 print(name[::-1]) #字符串倒序 列表
1 # names = "zhangyang gunyun xiangpeng xuliangchen" 2 names=['4ZhangYhang','#!Gunyun','xXiangpengt','ChenRonghua','Xuliangchen'] 3 print(names) 4 print(names[0],names[2]) 5 print(names[1:3]) #切片-顾头不顾尾-所在位子是连续的, 6 print(names[3]) 7 print(names[-1]) 8 print(names[-1:-3]) #name[-3:-0] 9 print(names[-2:]) # 切片的规则是 从左往右 最后0是可以忽略的10 print(names[0:3])11 print(names[:3]) #从头开始的0 也是可以忽略的12 print(names[::-1]) # 倒序13 #切片:就是另一种方式获取列表的值,它可以获取多个元素,可以理解为,从第几个元素开始,到第几个元素结束,获取他们之间的值14 15 names.append('LeiHaidong') #追加16 names.insert(1,'ChenRonghua') #按下标追加17 names.insert(3,'Xinzhiyu')18 print(names) #批量插入 ==不行,只能一个一个来19 20 # update21 names[2] = 'XieDi'22 print(names)23 24 # delete25 names.remove('ChenRonghua')26 del names[1] #==names.pop(1)27 names.pop(1)28 print(names)29 30 # 按下标查找31 print(names.index('XieDi'))32 print( names[names.index('XieDi')] )33 34 # 统计35 print(names.count('ChenRonghua'))36 # 清空37 names.clear() #清空38 names.reverse() #反转39 names.sort() # 排序40 print(names)41 names2 = [1,2,3,4]42 names.extend(names2) #扩展43 del names2 #删除变量44 print(names)45 46 # 下面是加上步长的47 nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]48 print(nums[::2]) # 这个代表取所有的元素,然后每隔2个元素取一个49 print(nums[1:8:3]) # 代表取第二个元素开始,到第八个结束,隔3个取一次50 51 #多维数组:列表里面可以再套列表,一个里面套一个列表,叫二维数组;一个里面套一个列表,里面的列表再套一个列表,这个叫三维数组,套几层就是几维52 names = ["niuniu", "houzi", "xiaoli", ["hhhh", "gggg"], "xiaoming", "xiaoli"]53 print(names)54 names3 = names.copy() # 修改names的参数,names3 保持不变,只copy第一层55 print(names3)56 names[3][0] ='二层'57 names[2] = '一层'58 print(names)59 print(names3) #修改names的值 names3 第一层不变,但是二层会变60 names[0] = "00000"61 print(names) 1 names = ["niuniu", "houzi", "xiaoli", "xiaoming"] 2 for i in names: # 列表循环 3 print(i) 4 5 # enumerate(cart_list) 取数组下标 6 #从第3位开始打印 - 循环 - 慢 7 list_1 = [1, 2, 3, 4, 5, 3, 6, ] 8 for index, list in enumerate(list_1): 9 if index == 3:10 print(index, list) # 3 4
元祖
元组的值不能改变,一旦创建,就不能再改变了 ,应用场景比如数据库连接,一些比较铭感切不能修改的地方
1 mysql_coon = ('192.168.1.109','root','123456',3306,'my_db')#定义元组 2 3 name_list = ("lary", "huni", "hony") 4 for ele in name_list: 5 print(ele) 6 7 for ele in name_list: 8 if ele == "lary": 9 print( "hello")10 break11 else:12 pass 字典
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
- 查询速度快,比列表快多了
- 比list占用内存多
1 info = { 2 'stu1101': "niuhanyang", 3 'stu1102': "houyafan", 4 'stu1103': "Baylor", 5 } 6 print(info.get('stu1105')) # 查找-不报错 7 print('stu1105' in info) # 返回一个True&false python2.7 info.has_key('1103') in py2.x 8 print(info) 9 print(info['stu1101']) #查找-明确值10 info['stu1101'] = '武藤兰' # 修改11 info['stu1104'] = '强势添加狗蛋' # 增加12 info.setdefault('name','goudan')13 print(info)14 15 info.pop('stu1101') #删除16 del info['stu1102'] #删除17 info.popitem() #随机删除18 print(info)19 b ={ '1111':"qqqqqq"}20 #内置方法21 print(info.values()) # 打印值values 不包括key的值22 print(info.keys()) # 打印keys23 info.update(b) # 合并字典,值相同覆盖,无值增加24 print(info) 1 info = { 2 'stu1101': "niuhanyang", 3 'stu1102': "houyafan", 4 'stu1103': "Baylor", 5 } 6 for i in info: #字典循环 7 print(i,info[i]) 8 9 for k,v in info.items(): #把字典变成列表--慢10 print(k,v) 三元运算
1 a = 5 2 b = 4 3 c = a if a > b else b # 如果a大于b的话,c=a,否则c = b ,如果不用三元运算符的话,就得下面这么写 4 print(a, c, b) 5 if a > b: 6 c = a 7 else: 8 c = b 9 print(a, c, b)10 11 nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]12 odd_num = [num for num in nums if num % 2 != 0] # 循环nums,如果nums里面的值,不能被2整除的话,就写到odd_num这个list中,也就是算奇数,等于下面这么写13 print(odd_num)14 15 odd_nums = []16 for num in nums:17 if num % 2 != 0:18 odd_nums.append(num)19 print(odd_nums)
模块&编码介绍
1 import sys #—环境变量 2 print(sys.path) #打印环境变量 3 print(sys.argv) #打印脚本绝对路径 4 print(sys.path[1]) #读取第3位 5 import os 6 cmd_res = os.system("ls -l") #执行命令不保存 cmd_res 如果执行成功返回0 代表成功 7 print("---->",cmd_res) #0 8 cmd_red = os.popen("ls -l") #打印内存空间地址 9 print("---->",cmd_red)10 cmd_ref = os.popen("ls -l").read() #popen 需要read()从内存空间取出数据11 print("---->",cmd_ref)12 13 #字符编码 转换14 msg = "你好"15 print(msg.encode('utf-8')) #转二进制 参数必写16 print(msg.encode("utf-8").decode(encoding='utf-8')) #转成字符串 数据运算
- 算术运算
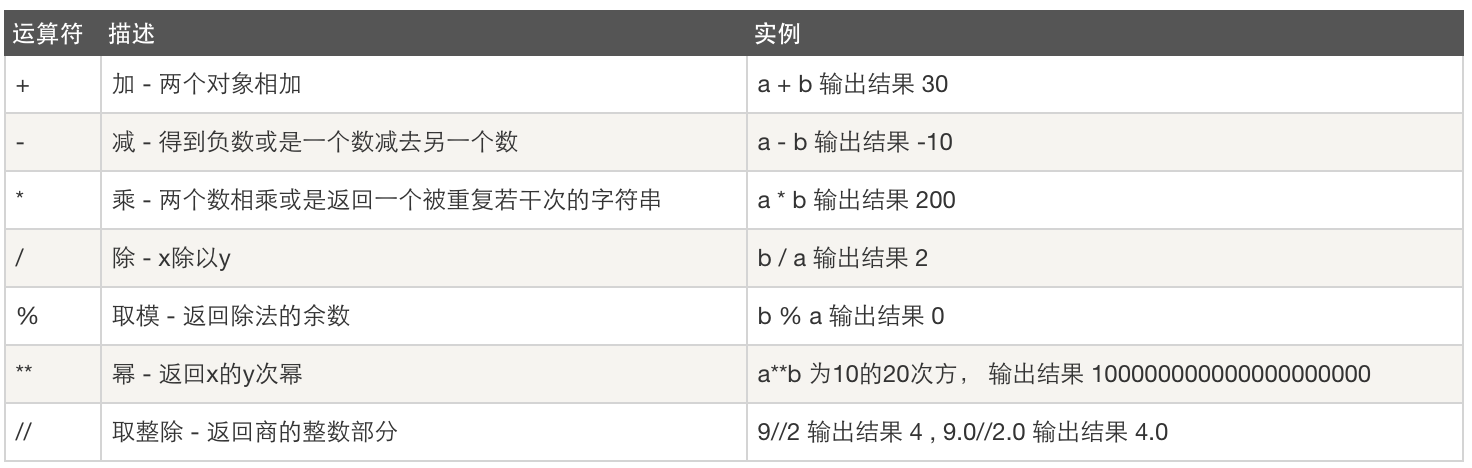
- 比较运算

- 赋值运算
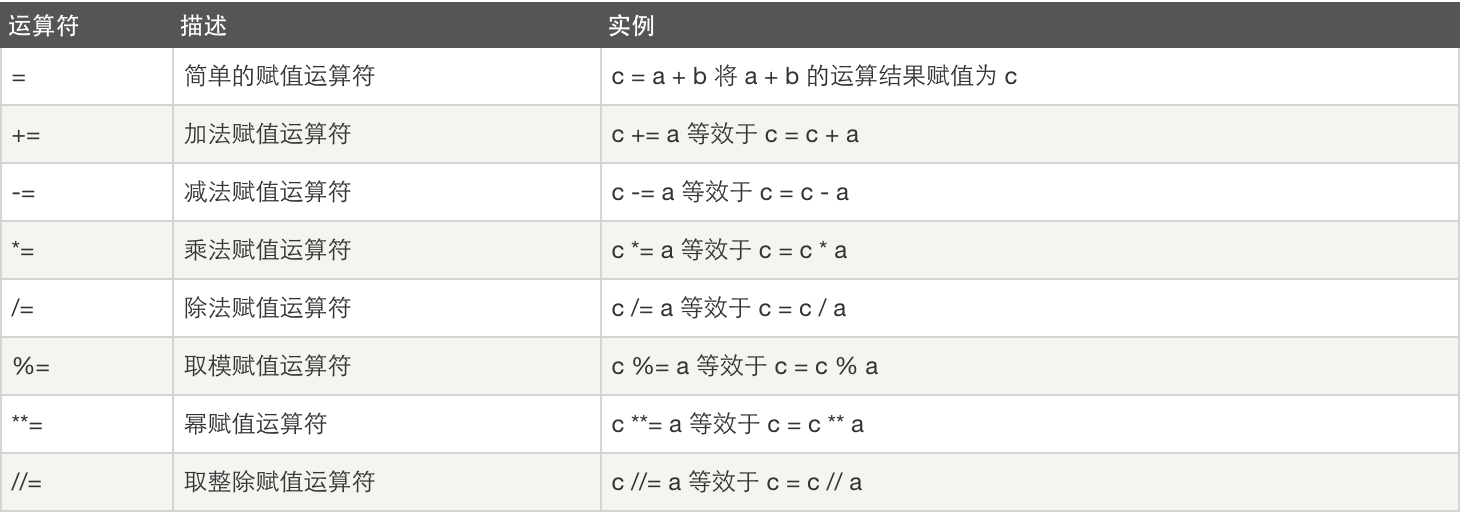
- 逻辑运算

- 成员运算

身份运算

- 位运算
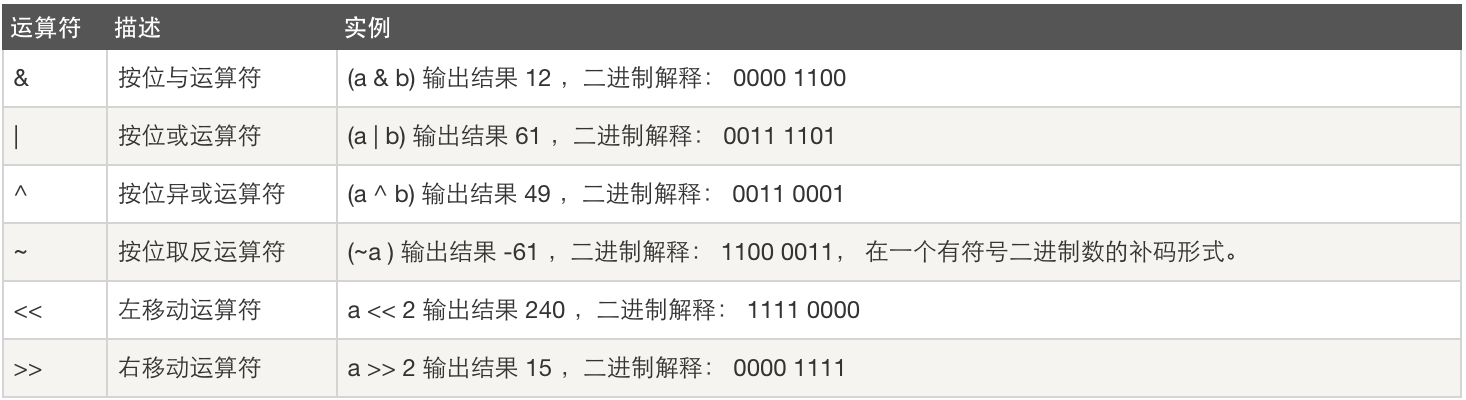
1 a = 60 # 60 = 0011 1100 2 b = 13 # 13 = 0000 1101 3 c = 0 4 5 c = a & b; # 12 = 0000 1100 6 print "Line 1 - Value of c is ", c 7 8 c = a | b; # 61 = 0011 1101 9 print "Line 2 - Value of c is ", c10 11 c = a ^ b; # 49 = 0011 0001 #相同为0,不同为112 print "Line 3 - Value of c is ", c13 14 c = ~a; # -61 = 1100 001115 print "Line 4 - Value of c is ", c16 17 c = a << 2; # 240 = 1111 000018 print "Line 5 - Value of c is ", c 19 20 c = a >> 2; # 15 = 0000 1111 21 print "Line 6 - Value of c is ", c
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与操作,按二进制位进行"与"运算。运算规则: 0&0=0; 0&1=0; 1&0=0; 1&1=1; | (A & B) 将得到 12,即为 0000 1100 |
| | | 按位或运算符,按二进制位进行"或"运算。运算规则: 0|0=0; 0|1=1; 1|0=1; 1|1=1; | (A | B) 将得到 61,即为 0011 1101 |
| ^ | 异或运算符,按二进制位进行"异或"运算。运算规则: 0^0=0; 0^1=1; 1^0=1; 1^1=0; | (A ^ B) 将得到 49,即为 0011 0001 |
| ~ | 取反运算符,按二进制位进行"取反"运算。运算规则: ~1=0; ~0=1; | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 二进制左移运算符。将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。将一个数的各二进制位全部右移若干位,正数左补0,负数左补1,右边丢弃。 | A >> 2 将得到 15,即为 0000 1111 |
- 运算符优先级
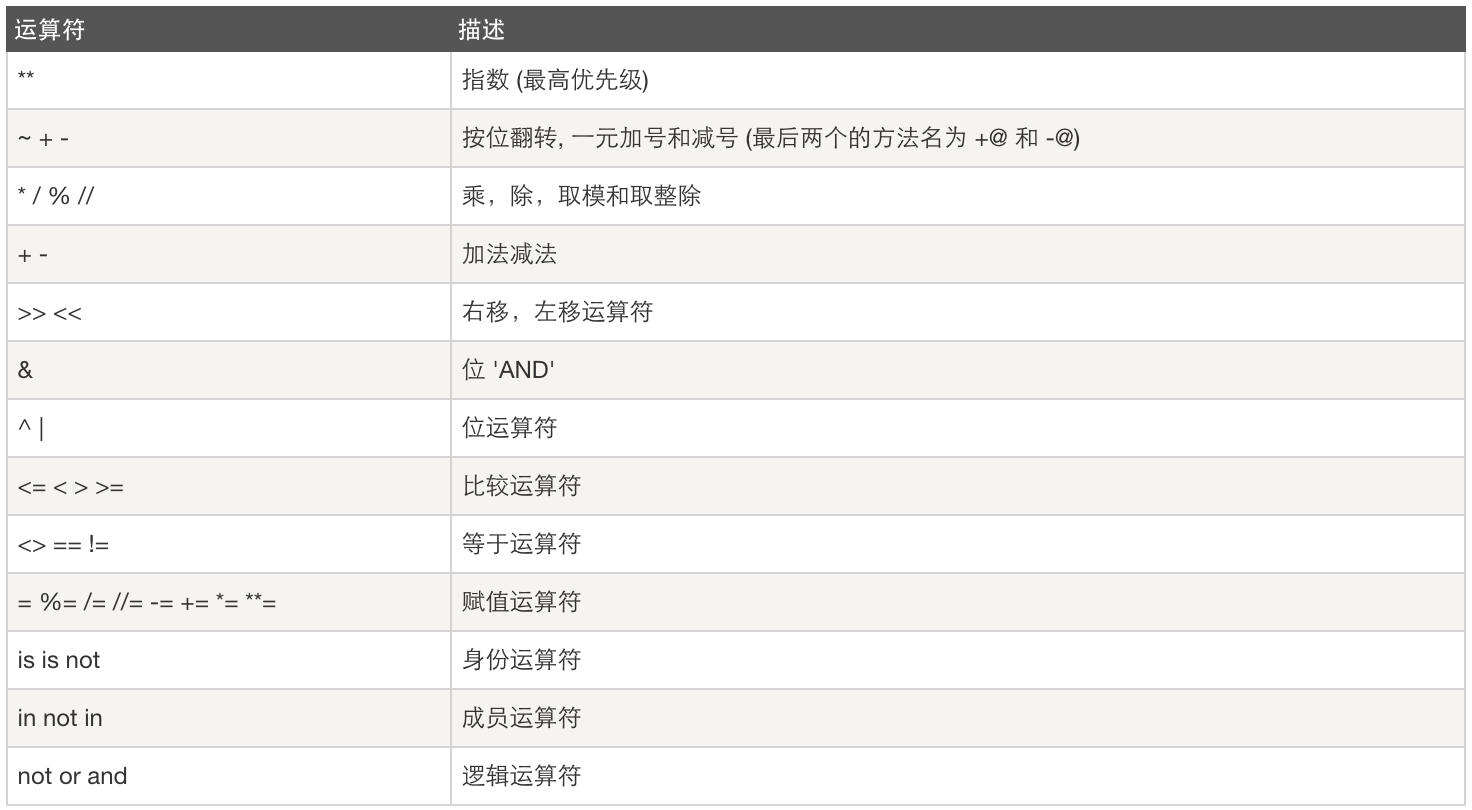
更多内容:
资料补充
1 print(" \033[31;1m 狗贼哪里走!!! \033[0m") #高亮展示 2 3 4 av_catalog = { 5 "欧美":{ 6 "www.youporn.com": ["很多免费的,世界最大的","质量一般"], 7 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], 8 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], 9 "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]10 },11 "日韩":{12 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]13 },14 "大陆":{15 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]16 }17 }18 19 av_catalog['大陆']['1024'][1] = '可以在国内做镜像'20 print(av_catalog)21 av_catalog.setdefault('台湾',{ 'www.baidu.com':[1,2]}) #创建新的字典值 如果字典中有值返回,无值创建22 print(av_catalog)23 24 c = dict.fromkeys([1,2,3],'test') #c初始化一个新的字典25 print(c)26 #坑27 c = dict.fromkeys([1,2,3],[1,{ 'name':'jinyu'},444]) #多层修改一个 全部修改28 print(c)29 c[1][1]['name'] = 'baylor chen'30 print(c)